



会社の中や公的機関に提出する書類でお馴染みの「Excel文書」。
「作成するのも大変だけど、読み取りや処理をさせるのも大変だ!」と思われている方は多いのではないのでしょうか?
Excel文書は人間にとっては見やすい書類にはなりますが、コンピュータにとっては処理しにくい書類の代表格となっています。
今回は、Excel文書をChatGPTをはじめとする生成AIに読み取らせて回答精度を向上させる前処理の方法を、製造業向け生成AI「SPESILL」を提供する株式会社ファースト・オートメーションの田中健太CTOが厳選して3種類のアプローチで解説します!
本記事を読むことがオススメの方!
・生成AIや大規模言語モデル(LLM)の活用に、検索拡張生成(RAG)を活用している人
・チーム専用の生成AIやLLMの導入に向けて、独自の生成AIにするためのチューニングをしていきたい人
・社内に溢れるExcel文書の「負債」を生成AIやLLMでどうにかしたい人
もくじ
LLMを悩ませる”Excel文書”とは?
今回の記事で紹介する、Excel文書とは「セルに文書を書いたり、オブジェクトや画像を挿入することで、いわゆる一般的な文書を作成しているExcelファイル」のことを指しています。
そもそも、一般的な文書作成では「Wordを使えばよいのでは?」と思われるかもしれませんが、以下の点からExcel文書にも利便性があると考えられます。
- 枠を使って、グルーピングすることでドキュメントの構成が見やすくなる
- セルを使うことで、空白や文字の開始位置を正確に制御でき、文字を綺麗に揃えやすい
- 先に一枚絵を作ってしまって、後からページの切り方を調整できる
- グラフやオブジェクトも入れられる
- 従業員やチームメンバーが書類を作成しやすい「フォーマット」として活用できる
Excel文書は、WordやPowerPointと比べて文書を 『整えながら自由に』 書くことができる点が特徴です。特に製造業では、見積書や仕様書の作成によく利用されています。
しかしながら、人間にとって素晴らしい利点を持つExcel文書は、生成AIをはじめとするコンピュータにとっては解析が難しいのが実情です。情報工学やプログラムの観点から見ると、Excel文書を解析して生成AIやLLMにデータを与えるためには下記のようなデメリットが生じます。
- 文字だけでなく、枠の構造を視覚的に理解させる必要がある
- セルの大きさやセルからの文字のはみ出しなどもレイアウトの一部であることを認識する必要がある
- ページの切り方がちゃんと設定されていないと、どこがページの区切りか分からない
- グラフやオブジェクトも扱う必要がある
【厳選3選】Excel文書の解析を悩ませた、実例の紹介
製造業向けの生成AI開発を手がけるファースト・オートメーションではこれまで、数多くのExcel文書を扱ってきました。それらの中から、特に解析が難しかったExcel文書の事例を厳選して3つ紹介します。
※あくまでサンプルとして作ったものであり、実際の企業のものではありません
①枠線で構造化
枠線を使って文書の構造化を行っているExcel文書の事例で、工程管理書など製造業でよく利用されている事例の筆頭格です。
生成AIやLLMに読み取りさせるために難しい点は、個々のセルではく枠線を認識する必要があるというところです。サンプルにあるように、画像も挿入されているため、画像も含めて認識させる必要が生じます。


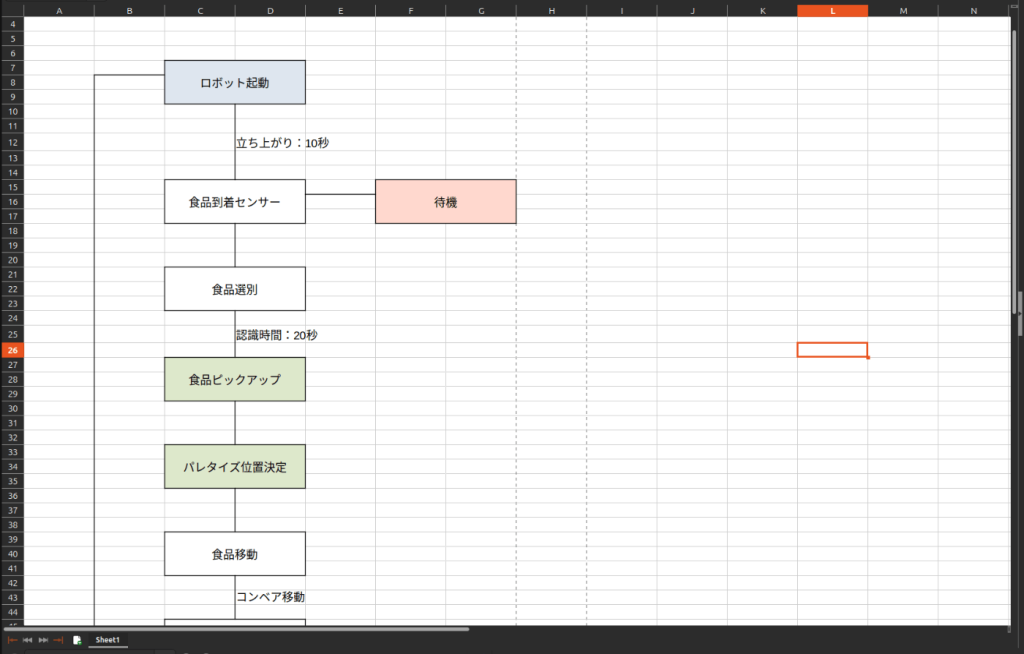
②セルでフローチャート
オブジェクトやセルを駆使してフローチャートを作成している例です。
セルの枠線やスタイル、配置に意味があるため、それらを生成AIやLLMに認識させる必要があります。

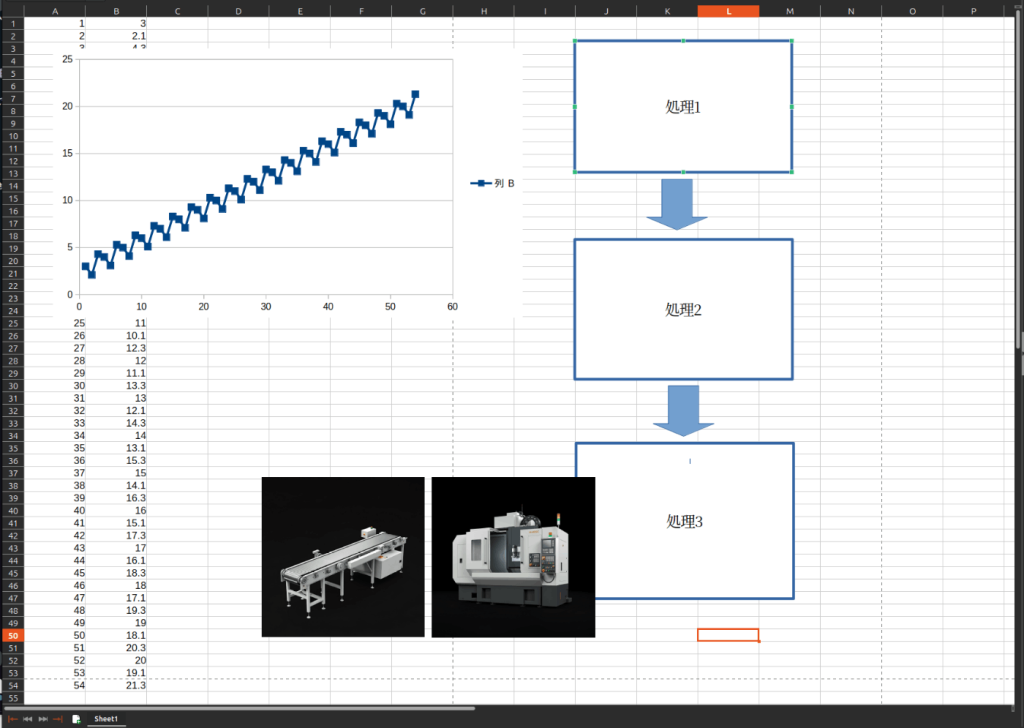
③オブジェクトや画像、グラフの混在
LLMの中でも極めて扱いづらい種類となるExcel文書が、オブジェクトや画像、グラフが混在しているものです。
基本的にはExcel文書そのものを画像として扱い、LLMの画像入力で処理する方法がやりやすいと考えられます。フローチャートなどでは、「mermaid」でテキスト化するという方法もあります。

ファースト・オートメーションで取り組んできた解析方法
ここからのパートでは、実際にExcel文書を生成AIやLLMで扱うためにファースト・オートメーションがトライしてきたことの一部を紹介します。今回は厳選して3種類のアプローチを紹介します。
- openpyxl等を使ってExcelをそのままパースする
- PDFに変換してPDFや画像として扱う
- PDF変換時にページの区切りをちゃんとする
アプローチ1:openpyxlなどを使ってExcelをそのままパースする
ステップ1:テキスト情報の抽出
Excel文書を扱う上で最も簡単な方法は、openpyxl等のExcelパースツールで、文字列のみを抽出する方法と考えられます。以下のコードではExcelファイルをopenpyxlで読み込み、各シート毎に文字列抽出して保存しています。
from openpyxl import load_workbook
workbook = load_workbook("<Excelファイルのパス>", data_only=True)
extracted_data = {}
for sheet_name in workbook.sheetnames:
sheet = workbook[sheet_name]
sheet_text = []
for row in sheet.iter_rows(values_only=True):
for cell in row:
if cell is not None:
sheet_text.append(str(cell))
extracted_data[sheet_name] = "\n".join(sheet_text)
print(extracted_data)ステップ2:表として読み込む
上記の方法では、全てのセルをテキストとして読み込ませて結合しているだけのため、表としての情報がすべて失われています。
そこで、pandasを使用することで、Excelを表として読み込み、Markdownなどで出力することができます。ただし、セル毎に要素が格納されていると見なすので、上の実例①「枠線で構造化」で示したような手動で書かれた枠線に沿った表はその通りにはなりません。
Excel文書ではない、構造化されたテーブルデータであればこの方法で十分と考えられます。
import pandas as pd
excel_data = pd.read_excel("<Excelファイルのパス>", sheet_name=None)
markdown_data = {}
for sheet_name, df in excel_data.items():
markdown_content = df.to_markdown(index=False, tablefmt="pipe")
markdown_data[sheet_name] = markdown_content
print(markdown_data)ステップ3:オブジェクト内のテキストの抽出
以下のようなExcelファイルをChatGPTに与えて質問すると、ファイルが空であるという内容が返ってきてしまいます。さて、何が起きているのでしょう?

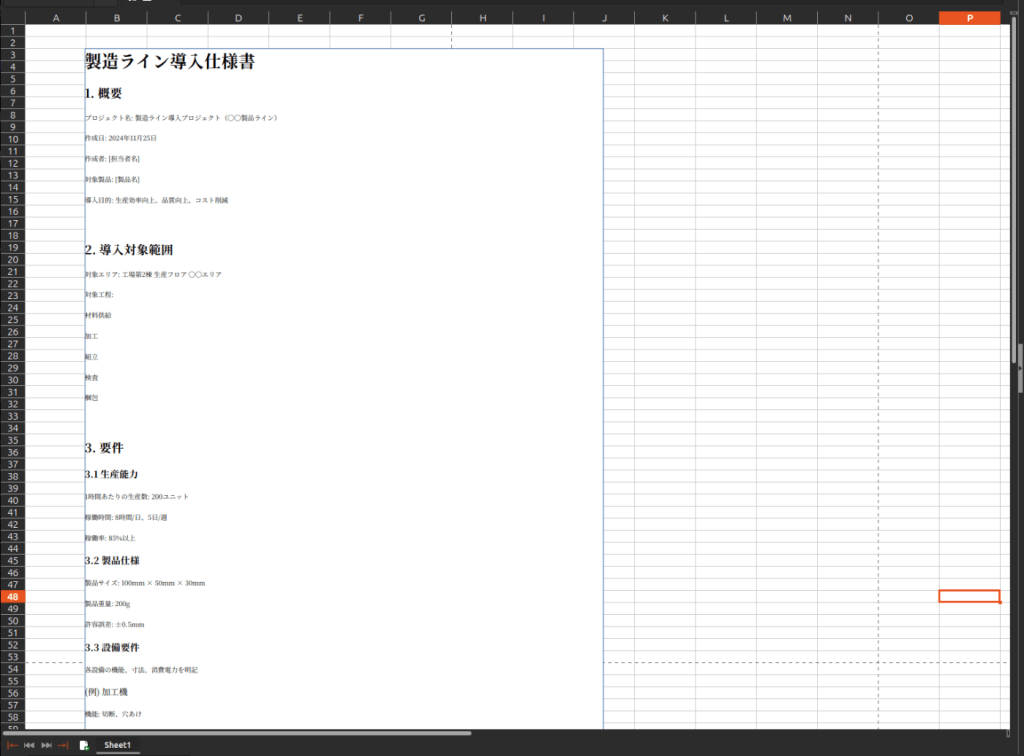
実はこのExcelファイルは、セルに文字が書かれているのではなく、矩形オブジェクトの中にテキストが埋められているという形となっています。
そのため、セルのパースだけではなく、オブジェクト内のテキストのパースが必要になります。
残念ながらExcelのオブジェクトはopenpyxlやpanadasでパースすることができず、Excel内のファイルを直接見に行って取得する必要があります。
xlsxなどのOfficeファイルはzipファイルなので、zipの中にある特定のxmlファイルにアクセスし、パースすることでこの情報を取得することができます。
import zipfile
from xml.etree import ElementTree as ET
textbox_contents: list[str] = []
with zipfile.ZipFile("<Excelファイルのパス>", "r") as z:
for file_name in z.namelist():
if "drawings" not in file_name:
continue
ns_xdr = "{http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing}"
ns_a = "{http://schemas.openxmlformats.org/drawingml/2006/main}"
with z.open(file_name) as f:
try:
tree = ET.parse(f)
root = tree.getroot()
except ET.ParseError as e:
print(f"Error parsing XML from file {file_name}: {e}")
continue
for two_cell_anchor in root.iter(f"{ns_xdr}twoCellAnchor"):
for textbox in two_cell_anchor.iter(f"{ns_xdr}txBody"):
text_content = ""
for paragraph in textbox.iter(f"{ns_a}p"):
paragraph_content = ""
for text in paragraph.iter(f"{ns_a}t"):
if text.text:
paragraph_content += text.text
text_content += "\n" + paragraph_content
textbox_contents.append(text_content)
print(textbox_contents)ステップ4:グラフ情報の抽出
次はExcel内のグラフ情報の抽出です。

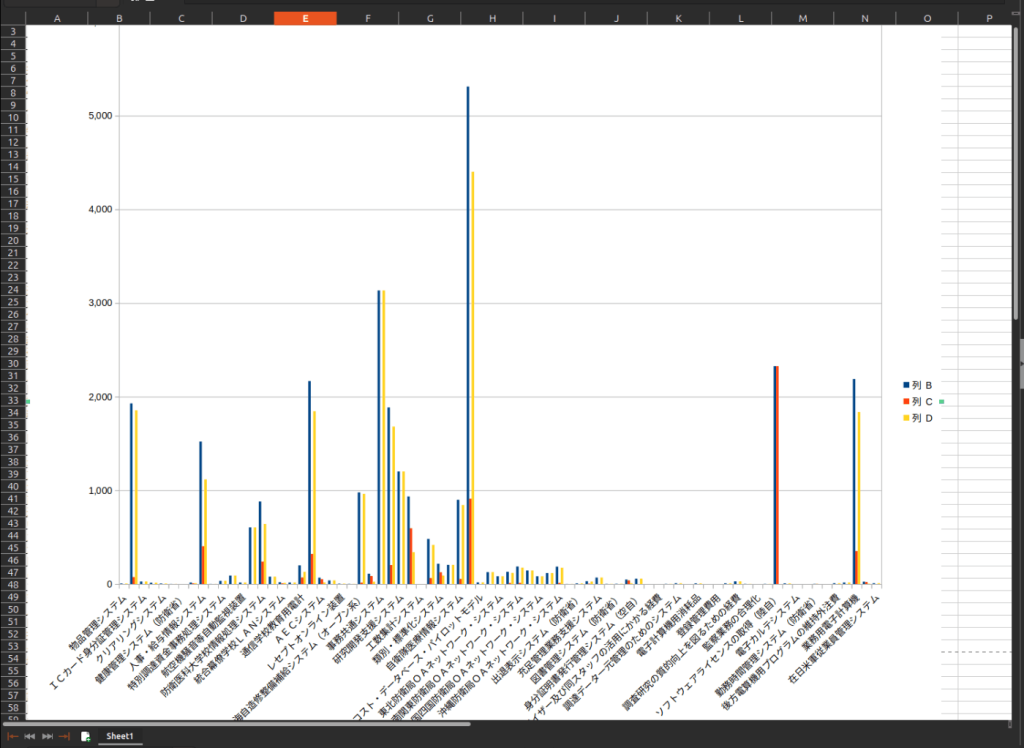
グラフは画像として抽出してもよいのですが、どのデータを参照しているかが分かるようになっているので、生成AIやLLMに与える上では、むしろデータを抽出して与えるという方法も有りかと考えられます。
以下では先ほどと同様に、Excel内のzipファイルの中からチャート情報のxmlファイルを読み込んで、padansのデータフレームに変換しています。
import zipfile
import pandas as pd
from xml.etree import ElementTree as ET
def parse_xml_for_chart(xml_data):
try:
root = ET.fromstring(xml_data)
except ET.ParseError as e:
print(f"Error parsing XML: {e}")
return {}
ns = {"c": "http://schemas.openxmlformats.org/drawingml/2006/chart"}
data = {}
for series in root.findall(".//c:ser", namespaces=ns):
cv_elem = series.find("./c:tx/c:strRef/c:strCache/c:pt/c:v", namespaces=ns)
if cv_elem is None:
series_name = ""
else:
series_name = cv_elem.text
categories = [
pt.find("./c:v", namespaces=ns).text
for pt in series.findall("./c:cat/c:strRef/c:strCache/c:pt", namespaces=ns)
]
series_values = [
pt.find("./c:v", namespaces=ns).text
for pt in series.findall("./c:val/c:numRef/c:numCache/c:pt", namespaces=ns)
]
data[series_name] = dict(zip(categories, series_values))
return data
doc_zip = zipfile.ZipFile("<Excelファイルのパス>")
zipped_files = doc_zip.namelist()
chart_tables: list[pd.DataFrame] = []
for file in zipped_files:
if file.startswith(f"{file_type}/charts/chart") and file.endswith(".xml"):
xml_data = doc_zip.read(file)
data = parse_xml_for_chart(xml_data)
df = pd.DataFrame(data)
chart_tables.append(df)
print(chart_tables)アプローチ2:PDFに変換してPDFや画像として扱う
最近になって、画像や表を含んだPDFを視覚情報に基づいてかなり精度高く解析できるツールが増えてきました。
つまり以下のような流れでExcelをPDFに変換して、このようなツールを使うことで視覚情報も含めてある程度うまくパースすることができます。

実際に、視覚情報も考慮したPDFパーサやAIツールには以下のようなものがあります。
※商用での使用に関しては必ずそれぞれのライセンスを確認してください。
- opendatalab / MinerU:https://github.com/opendatalab/MinerU
- DS4SD / docling:https://github.com/DS4SD/docling
- getomni-ai / zerox:https://github.com/getomni-ai/zerox
- run-llama / llama_parse:https://github.com/run-llama/llama_parse
- pymupdf / RAG:https://github.com/pymupdf/RAG
- kotaro-kinoshita / yomitoku:https://github.com/kotaro-kinoshita/yomitoku
- QwenLM / Qwen2-VL:https://github.com/QwenLM/Qwen2-VL
- ChatGPT-4o:https://openai.com/index/hello-gpt-4o/
- PDF support (beta):https://docs.anthropic.com/en/docs/build-with-claude/pdf-support
①MinerU、②docling、⑥yomitokuは表や画像を検出する検出器やOCRを行う機械学習モデルを使ってパースを行っています。その中でyomitokuはさらに日本語に特化した機械学習モデルを使っています。
一方で③zeroxや④llama_parseはChatGPTなどのLLMを用いてパースを行います。
後半の⑦Qwen2-VLと⑧GPT-4oを使う場合はPDFを画像に変換して使用します。これらのモデルはOCRの性能が高いため、画像から文書ファイルを読むことができます。
また、プログラム的にExcelをPDFに変換する際は下記のunoconvやgotenbergなどが使えるかと思います。
- unoconv / unoconv:https://github.com/unoconv/unoconv
- Gotenberg:https://gotenberg.dev/
これらの方法により、例えばExcel文書の実例①で示したような枠線で構造化されたデータやフローチャートもうまく読み込むことができるようになります。
ファースト・オートメーションでも、LLMを用いたPDF→Markdown変換を行うことで表やフローチャートをうまく抽出するツールを開発しており、それを用いることで”Excel文書”の例Aで出したファイルを以下のようにMarkdownの表としてテキスト化することができます。


同様にExcel文書の実例②のファイルは以下のようにmermaidとしてテキスト化されます。


アプローチ3:PDF変換時にページの区切りを明確に設定する
アプローチ2でExcelをPDFに変換する際に、Excel側でちゃんとページの設定がされていないと変なところでページが切れてしまうという問題が発生します。
例えば、防衛省が出しているシステム経費の実績の資料では、これをそのままPDFに変換するとその下のように表が途中で切れたPDFが生成されてしまいます。
これは適切にユーザがページの区切りを設定しておらず、Office側で適当なところで区切ってしまうために発生してしまう問題です。

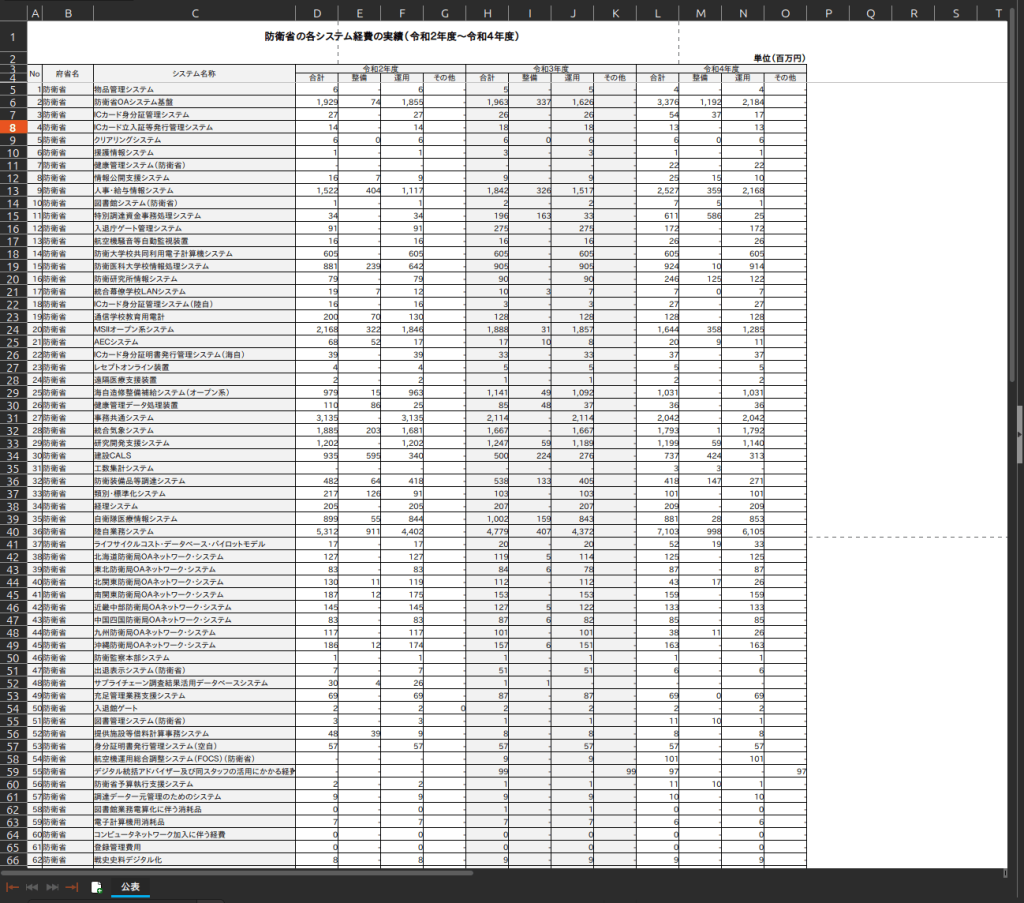


unoconvやgotenbergはページの区切りまで調整することができないため、この辺りをよしなにやってPDF変換してくれるツールを用いる必要があります。
APIも提供されているWebサービスだと以下のようなものがあります。
- Adobe Acrobat Services API:https://experienceleague.adobe.com/ja/docs/acrobat-services-learn/tutorials/overview
- iLoveAPI:https://www.ilovepdf.com/ja/blog/what-is-ilovepdf-developers
しかし、これらのツールは一定の無料枠があるとはいえ、プロダクト内での使用を考えると有料課金が必要になります。
「たかがExcel→PDF変換で課金したくないなぁ」という思いと、ファースト・オートメーションとしてはこのアプローチを自分たちでも調節できるようオリジナルで作っておきたいという背景もあり、ChatGPTにやり方を教えてもらいつつ、自分たちで作ることにしました。
アプローチ3の技術についてはGithubで公開しており、Dockerを使用してExcel→PDF変換を行うAPIサーバとして使用できるようになっています。
これでExcel→PDF変換で上記のような有料ツールに頼らずに済みます!!
実際に先程の防衛省資料は以下のようにちゃんと一枚ページで出力されるようになります。

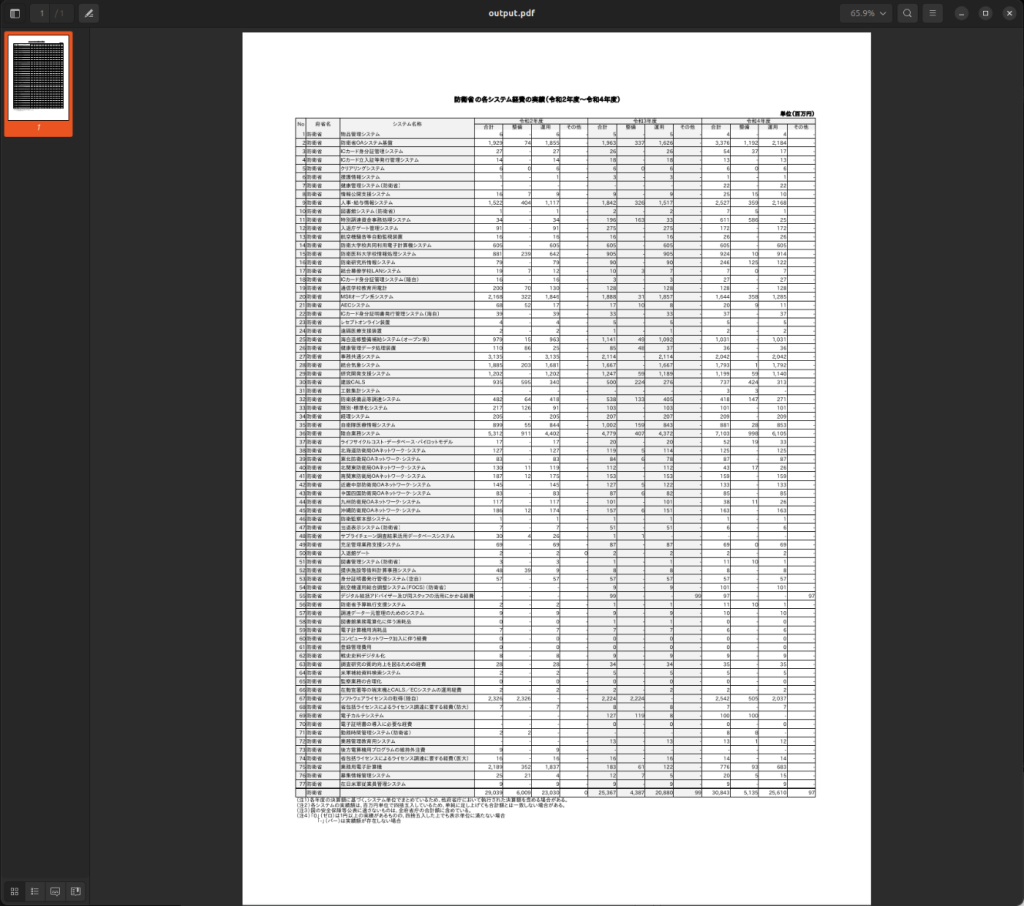
仕組みとしては、LibreOffice(Linuxで動くフリーのOfficeライクなツール)を内部的にサーバとして稼働させておいて、それに対してAPIでセル情報やページ情報などにアクセス・編集し、最終的にPDFに変換してもらうというようになっています。
LibreOfficeをサーバとして立ち上げるコマンドは以下になります。
soffice --accept=socket,host=localhost,port=2002;urp;StarOffice.ServiceManager --headlessこれを立ち上げた状態で、「uno」というpythonパッケージを使用することで、セルやページの情報にアクセスできるようになります。
import sys
sys.path.append("/usr/lib/python3/dist-packages/") # unoはLibreOfficeと一緒にシステムのPythonパッケージとしてインストールされるのでパスを登録しておく
import uno
local_context = uno.getComponentContext()
resolver = local_context.ServiceManager.createInstanceWithContext(
"com.sun.star.bridge.UnoUrlResolver", local_context
)
context = resolver.resolve(
f"uno:socket,host=localhost,port=2002;urp;StarOffice.ComponentContext"
)
desktop = context.ServiceManager.createInstanceWithContext(
"com.sun.star.frame.Desktop", context
)
input_url = "file:///<Excelファイルのパス>"
document = desktop.loadComponentFromURL(input_url, "_blank", 0, ())
for sheet in self.document.Sheets:
cell = sheet.getCellByPosition(0, 0)
print(cell)ここまでの対策によって、様々な”Excel文書”から精度高く情報抽出ができるようになってきました。
さいごに
RAGとLLMのシステムで扱いの難しいExcel文書をうまく扱うための手法を厳選して3種類のアプローチを紹介させていただきました。
実際にファースト・オートメーションのプロダクトでは、今回紹介した方法を複合的に使用して文書の解析を行っています。ここで紹介したサンプルよりももっと複雑なExcel文書も多く、まだまだ読み取りの精度の改善を進めていっています。
無料で、有料級の限定コンテンツを配信中!
メールマガジン「製造DX.com-Plus」の登録はこちらから
製造DX.comでは、製造現場の生産性向上に役立つ先進的な情報を発信するメールマガジン「製造DX.com-Plus」を配信しています。メールマガジン読者限定の情報を配信しておりますので、ぜひご登録ください!


運営会社について
製造DX.comを運営する株式会社ファースト・オートメーションは製造業に特化した生成AI「SPESILL(スペシル)」を提供しています。製造DX.comでは生成AIに関する研究開発の成果を投稿しています。